For Candidates with 3–5 Years of Experience
Deloitte is one of the Big Four consulting firms with a massive Salesforce practice. Their interviews for mid-level Salesforce developers are rigorous — expect a mix of deep technical questions, scenario-based problems, and consulting-mindset challenges. This guide covers the most frequently asked questions with answers calibrated for 3–5 years of experience.
📋 Table of Contents
- Apex & Core Development (Q1–Q12)
- Lightning Web Components & UI (Q13–Q20)
- Integration & APIs (Q21–Q28)
- Data Modeling & SOQL/SOSL (Q29–Q34)
- Security, Sharing & Governance (Q35–Q39)
- Automation & Flow (Q40–Q43)
- DevOps, Testing & Deployment (Q44–Q47)
- Scenario / Consulting-Mindset (Q48–Q50)
SECTION 1: Apex & Core Development
Q1. What is the difference between trigger.new and trigger.newMap in Apex triggers? When would you use each?
Answer:
Trigger.new returns a List of the new versions of sObject records involved in the trigger. Trigger.newMap returns a Map<Id, sObject> of those same records, keyed by their record ID.
When to use each:
- Use
Trigger.newwhen you need to iterate over all records in order or when records don’t yet have IDs (i.e., inbefore insertcontext, IDs aren’t assigned yet, soTrigger.newMapis null). - Use
Trigger.newMapwhen you need fast O(1) lookup of a specific record by ID — for example, when comparing parent records or doing cross-object lookups.
Example scenario: In a before update trigger, if you need to find which records changed a specific field, you’d do:
for (Id recId : Trigger.newMap.keySet()) {
if (Trigger.newMap.get(recId).Status__c != Trigger.oldMap.get(recId).Status__c) {
// field changed
}
}
Q2. Explain the concept of “bulkification” in Apex. Why is it critical at Deloitte-level enterprise implementations?
Answer:
Bulkification means writing Apex code that can handle up to 200 records per transaction — the maximum records Salesforce processes in a single trigger execution — without hitting governor limits.
Key principles:
- Never put SOQL/DML inside a loop. Always collect IDs, query outside the loop, then process in a map.
- Use collections (Lists, Maps, Sets) to batch operations.
- Aggregate logic before committing DML.
Why it matters at enterprise scale: Deloitte implementations often involve data migrations, batch ETL loads, and integrations pushing thousands of records. Non-bulkified code will throw LimitException errors in production, causing data integrity failures that are expensive to remediate on client engagements.
Bad pattern:
for (Account acc : Trigger.new) {
List<Contact> contacts = [SELECT Id FROM Contact WHERE AccountId = :acc.Id]; // SOQL in loop!
}
Good pattern:
Set<Id> accIds = Trigger.newMap.keySet();
Map<Id, List<Contact>> contactMap = new Map<Id, List<Contact>>();
for (Contact c : [SELECT Id, AccountId FROM Contact WHERE AccountId IN :accIds]) {
if (!contactMap.containsKey(c.AccountId)) contactMap.put(c.AccountId, new List<Contact>());
contactMap.get(c.AccountId).add(c);
}
Q3. What is a “future method” and what are its limitations? How does it compare to Queueable Apex?
Answer:
A @future method is an Apex method that runs asynchronously in its own transaction. It’s used when you need to perform callouts from triggers or escape a governor limit context.
Limitations of @future:
- Cannot be called from another
@futureorBatchclass - Cannot pass sObjects as parameters (only primitives or collections of primitives)
- No job chaining
- No way to monitor job status
Queueable Apex advantages over @future:
| Feature | @future | Queueable |
|---|---|---|
| Job Chaining | ❌ | ✅ (via System.enqueueJob in execute()) |
| sObject parameters | ❌ | ✅ |
| Job ID returned | ❌ | ✅ |
| Can call from Batch | ❌ | ✅ |
Interview tip: At Deloitte, the preference in modern code is Queueable Apex for async processing unless the use case is very simple and legacy-constrained.
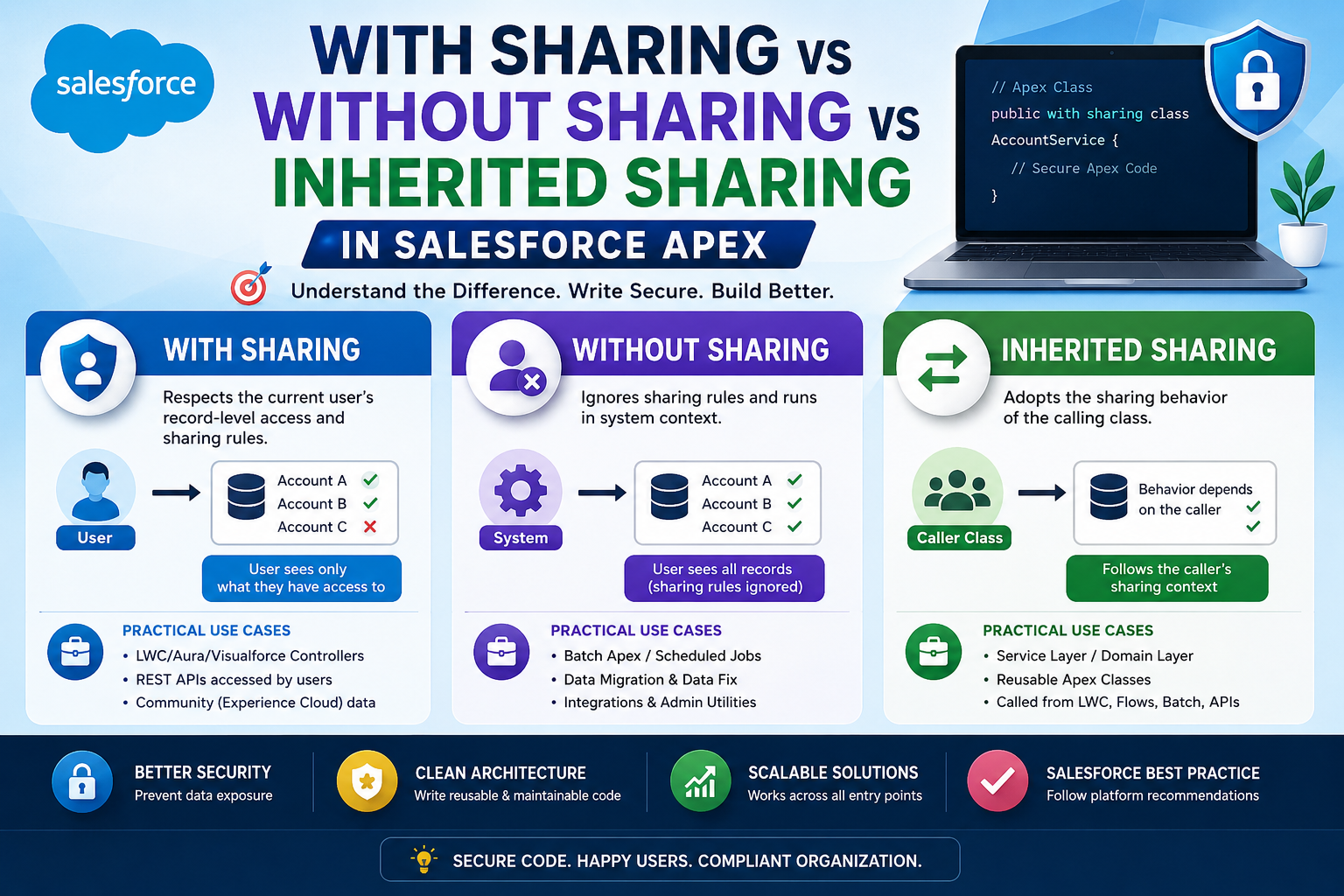
Q4. Explain the difference between with sharing, without sharing, and inherited sharing in Apex classes.
Answer:
These keywords control whether Org-Wide Defaults (OWD) and sharing rules are enforced when Apex code runs.
with sharing: Enforces the running user’s sharing rules. Records the user cannot access are excluded from SOQL results. Use for any class that processes user-facing data.without sharing: Ignores sharing rules entirely. The class can access all records regardless of user permissions. Use only for system-level operations like batch jobs or integration handlers where you need access to all records.inherited sharing: Introduced in API v48. The class inherits the sharing context of its caller. If called from awith sharingclass, it runs with sharing. This is the recommended default for utility/helper classes that shouldn’t dictate their own sharing behavior.
Best practice for Deloitte interviews: Always declare sharing on every class. Never leave it implicit. Use inherited sharing for service layer classes that are called from multiple contexts.
Q5. What is a Virtual vs Abstract class in Apex? Give a practical use case for each.
Answer:
Abstract class:
- Cannot be instantiated directly
- Can contain abstract methods (no implementation) that subclasses must override
- Use case: A base
TriggerHandlerframework where each trigger handler must implementhandleBeforeInsert(),handleAfterUpdate(), etc.
public abstract class TriggerHandlerBase {
public abstract void handleBeforeInsert(List<SObject> newRecords);
}
Virtual class:
- Can be instantiated
- Methods marked
virtualcan be optionally overridden - Use case: A base
EmailNotificationServicewhere subclasses can overridegetEmailTemplate()but don’t have to
public virtual class EmailNotificationService {
public virtual String getEmailTemplate() {
return 'DefaultTemplate';
}
}
Key difference: Abstract = subclass MUST override abstract methods. Virtual = subclass CAN override virtual methods.
Q6. What are governor limits you monitor most closely in an enterprise Apex context? How do you handle approaching limits?
Answer:
The limits I watch most closely are:
| Limit | Cap |
|---|---|
| SOQL queries per transaction | 100 |
| DML statements | 150 |
| DML rows | 10,000 |
| CPU time | 10,000ms (sync), 60,000ms (async) |
| Heap size | 6MB (sync), 12MB (async) |
| Callouts | 100 |
Strategies to handle near-limit scenarios:
- Offload to async: Move expensive processing to Queueable or Batch Apex to get a fresh set of limits.
- Batch Apex for large data volumes: Break 100k+ record operations into 200-record chunks.
- Use
Limitsclass proactively:Limits.getQueries()/Limits.getLimitQueries()to guard conditionally. - Avoid re-querying: Cache results in static variables within a transaction.
- Review automation stacking: At Deloitte, complex orgs often have Flows + Triggers + Process Builders firing together — audit and consolidate.
Q7. How do you implement the Trigger Handler pattern? Why does Deloitte prefer it over logic directly in triggers?
Answer:
The Trigger Handler pattern separates trigger logic from business logic by keeping triggers thin (just routing calls) and putting all logic in dedicated handler classes.
Standard trigger (thin):
trigger AccountTrigger on Account (before insert, before update, after insert, after update) {
AccountTriggerHandler handler = new AccountTriggerHandler();
if (Trigger.isBefore && Trigger.isInsert) handler.onBeforeInsert(Trigger.new);
if (Trigger.isAfter && Trigger.isUpdate) handler.onAfterUpdate(Trigger.new, Trigger.oldMap);
}
Why Deloitte prefers this:
- Testability: Handler classes are independently testable without trigger context
- Maintainability: Multiple developers can work on handlers without merge conflicts in a single trigger file
- One trigger per object rule: Prevents ordering issues from multiple triggers
- Bypass mechanism: Can add
TriggerSettings__ccustom metadata to disable triggers during data loads without deploying code
Q8. Explain the difference between Database.insert() with allOrNone=false vs. the insert DML statement.
Answer:
The standard insert DML statement uses all-or-none behavior by default: if any single record fails, the entire operation rolls back.
Database.insert(records, false) enables partial success: records that pass are committed, failed records are returned in Database.SaveResult[] with error details. Your code can then handle or log failures gracefully.
When to use partial DML at Deloitte:
- Integration handlers processing inbound data from external systems where some records may be malformed
- Batch jobs processing large datasets where you don’t want one bad record to block 199 others
- Always log failures to a custom Error Log object for client visibility
List<Database.SaveResult> results = Database.insert(accountList, false);
for (Database.SaveResult sr : results) {
if (!sr.isSuccess()) {
for (Database.Error err : sr.getErrors()) {
System.debug('Error: ' + err.getMessage());
// Log to Error_Log__c
}
}
}
Q9. What is @TestSetup and how does it improve test performance?
Answer:
@TestSetup is a method annotation that creates test data once per test class and rolls it back between test methods (each method gets a fresh copy of the data). Without it, every @isTest method creates its own data, multiplying DML operations.
@TestSetup
static void setup() {
Account acc = new Account(Name = 'Test Corp');
insert acc;
// Creates once, available to ALL test methods in the class
}
Performance benefit: In a test class with 20 test methods, @TestSetup reduces DML from 20× to 1× for setup data. This dramatically reduces test execution time in large Salesforce orgs with thousands of test methods — critical for Deloitte CI/CD pipelines.
Important nuance: @TestSetup data is re-queried at the start of each test method (it’s not shared in memory) — so any changes made in one test method don’t affect others.
Q10. How do you prevent recursive trigger execution in Salesforce?
Answer:
Recursive triggers occur when a trigger fires, its DML causes another trigger to fire on the same object, creating an infinite loop (or hitting Maximum trigger depth exceeded error).
Standard approach — static boolean flag:
public class TriggerHelper {
public static Boolean isExecuting = false;
}
trigger AccountTrigger on Account (after update) {
if (!TriggerHelper.isExecuting) {
TriggerHelper.isExecuting = true;
// logic here
TriggerHelper.isExecuting = false;
}
}
Limitation of boolean flag: It blocks ALL subsequent trigger executions in the transaction, even legitimate ones for different records.
Better approach — Set-based tracking:
public class TriggerHelper {
public static Set<Id> processedIds = new Set<Id>();
}
// In trigger: only process IDs not already in the set
This allows different records to be processed while preventing the same record from being processed twice.
Q11. What is the difference between SOQL and SOSL? When would you use SOSL?
Answer:
SOQL (Salesforce Object Query Language): Queries a single object and its related objects. Best for precise, field-specific queries when you know the object.
SOSL (Salesforce Object Search Language): Searches across multiple objects and fields simultaneously using text search. Returns a List<List<SObject>>.
Use SOSL when:
- You need to search across Account, Contact, Lead, and Opportunity simultaneously (global search)
- You’re building a search feature and don’t know which object has the data
- The search term could appear in multiple text fields
List<List<SObject>> results = [FIND 'Deloitte*' IN ALL FIELDS
RETURNING Account(Id, Name), Contact(Id, FirstName, LastName)];
SOSL limitation: Cannot be used in triggers (it’s expensive and may return unexpected results in bulk contexts). Minimum 2 characters required for search term.
Q12. Explain Platform Events and how they differ from Custom Notifications or Change Data Capture.
Answer:
Platform Events: A publish-subscribe messaging framework built on Salesforce’s event bus. Publishers fire events; any subscriber (Apex trigger, Flow, or external system) processes them asynchronously.
Change Data Capture (CDC): Automatically publishes change events when Salesforce records are created, updated, deleted, or undeleted. You don’t define the event — Salesforce does. Best for real-time data replication to external systems.
Custom Notifications: Push notifications delivered to Salesforce users in the app or mobile. Not for system-to-system communication.
| Feature | Platform Events | CDC | Custom Notifications |
|---|---|---|---|
| Direction | Any system | SF → External | SF → Users |
| Schema | You define | SF defines | N/A |
| Use case | Integration middleware | Data sync | User alerts |
| Replay available | ✅ (72 hrs) | ✅ (3 days) | ❌ |
Deloitte context: Platform Events are commonly used as an integration backbone — external systems publish events that Salesforce processes, decoupling systems and avoiding tight integration dependencies.
SECTION 2: Lightning Web Components & UI
Q13. Explain the LWC component lifecycle hooks in order of execution.
Answer:
LWC lifecycle hooks fire in this order:
constructor()— Called when component is created. DOM not yet rendered. Don’t access child components here.connectedCallback()— Called when component is inserted into the DOM. Use for initialization, event listener setup, or imperative data fetch.render()— Called to determine which template to render (used in conditional rendering scenarios).renderedCallback()— Called after every render (initial + subsequent). Use for DOM manipulation. Beware of infinite loops if you update reactive properties here.errorCallback(error, stack)— Called if a child component throws an error. Acts as an error boundary.disconnectedCallback()— Called when component is removed from DOM. Use for cleanup (removing event listeners, clearing timers).
Interview tip: A common Deloitte question is “where would you make a wire call vs. an imperative call?” — Wire calls are declarative and reactive (re-run when params change). Imperative calls in connectedCallback are useful for one-time fetches or when you need to handle the promise explicitly.
Q14. What is the difference between @track, @api, and @wire decorators in LWC?
Answer:
@api: Exposes a property or method as public — accessible from parent components. Used to pass data down the component tree. Any change from the parent triggers re-render.
@track: Makes a property reactive to deep mutations (nested object/array changes). In modern LWC (API 39+), all properties are reactive to top-level reassignment by default. @track is only needed when you mutate a nested property of an object without reassigning the object itself.
@wire: Declaratively connects a property or function to a Salesforce data source (Apex method, wire adapters like getRecord, getObjectInfo). Automatically refreshes when tracked parameters change.
@api recordId; // Public, passed from parent
@track filters = { status: 'Open', priority: 'High' }; // Deep reactivity needed
@wire(getOpportunities, { accountId: '$recordId' }) opportunities; // Reactive wire
Q15. How do you communicate between sibling LWC components?
Answer:
LWC components follow a unidirectional data flow — data flows down via @api, events bubble up. Siblings can’t communicate directly.
Approaches for sibling communication:
- Through a common parent: Child A fires a custom event → Parent catches it → Parent updates
@apiproperty on Child B. This is the recommended pattern for tightly related components. - Lightning Message Service (LMS): The standard Salesforce-provided pub/sub service. Components subscribe to a Message Channel; any component on the page can publish to it. Works across DOM hierarchies, Visualforce iframes, and Aura components.
// Publisher
import { publish, MessageContext } from 'lightning/messageService';
import ACCOUNT_SELECTED from '@salesforce/messageChannel/AccountSelected__c';
publish(this.messageContext, ACCOUNT_SELECTED, { accountId: this.selectedId });
// Subscriber
import { subscribe, MessageContext } from 'lightning/messageService';
this.subscription = subscribe(this.messageContext, ACCOUNT_SELECTED, (message) => {
this.handleMessage(message);
});
- Custom pub/sub library (legacy): A shared singleton module. Avoid in new development — LMS is the official replacement.
Q16. What is @salesforce/apex wire adapter vs. imperative Apex call? When would you choose each?
Answer:
Wire (reactive):
@wire(getAccountList, { industry: '$selectedIndustry' })
wiredAccounts({ error, data }) { ... }
- Automatically called and re-called when
$selectedIndustrychanges - Results are cached by Salesforce
- Best for read-only data that depends on reactive inputs
Imperative:
async handleSearch() {
try {
const result = await getAccountList({ industry: this.selectedIndustry });
this.accounts = result;
} catch(error) { ... }
}
- Explicit control over when the call is made
- Can be triggered by user action (button click)
- Required for mutations (insert/update/delete) — wire is read-only
- Needed when you want to handle loading states or errors differently
Deloitte preference: Use wire for initial data loading; use imperative for user-triggered actions, form submissions, and any server-side DML operations.
Q17. What is the difference between lightning-record-form, lightning-record-view-form, and lightning-record-edit-form?
Answer:
| Component | Read | Write | Control over layout |
|---|---|---|---|
lightning-record-form | ✅ | ✅ | Limited |
lightning-record-view-form | ✅ | ❌ | Full control over fields |
lightning-record-edit-form | ❌ | ✅ | Full control over fields |
lightning-record-form: Quickest to implement. Renders a complete form in view or edit mode. Good for standard use cases but limited customization.
lightning-record-view-form: Use when you need a read-only display with custom layout, conditional rendering of fields, or custom styling around specific fields.
lightning-record-edit-form: Use when you need a custom edit form — custom submit logic, custom validation messages, conditional field visibility, or complex field dependencies.
Deloitte tip: For complex forms on client projects, lightning-record-edit-form with custom validation using reportValidity() is the standard pattern because it gives full control while still honoring field-level security.
Q18. Explain slots in LWC. What are named slots and default slots?
Answer:
Slots allow parent components to inject HTML content into designated areas of a child component — enabling flexible, reusable component composition.
Default slot: Accepts any content placed between the child component tags in the parent.
<!-- Child: card.html -->
<div class="card"><slot></slot></div>
<!-- Parent -->
<c-card>
<p>This content goes into the default slot</p>
</c-card>
Named slots: Allow multiple injection points with specific names.
<!-- Child: modal.html -->
<div class="modal">
<div class="header"><slot name="header"></slot></div>
<div class="body"><slot></slot></div>
<div class="footer"><slot name="footer"></slot></div>
</div>
<!-- Parent -->
<c-modal>
<span slot="header">Confirm Delete</span>
<p>Are you sure?</p>
<button slot="footer" onclick={handleConfirm}>Yes, Delete</button>
</c-modal>
Deloitte use case: Modal components, card containers, and layout wrappers at the design system level heavily use named slots to allow teams to compose pages without rebuilding containers.
Q19. What is @salesforce/label, @salesforce/i18n, and how do you handle internationalization in LWC?
Answer:
@salesforce/label: Imports Custom Labels for use in JavaScript or templates. Custom Labels are translatable strings stored in Salesforce — they automatically serve the right translation based on the user’s language setting.
import SAVE_BUTTON from '@salesforce/label/c.SaveButton';
import ERROR_MESSAGE from '@salesforce/label/c.ErrorMessage';
@salesforce/i18n: Provides locale-specific formatting — number format, currency, date format — based on the user’s locale.
import LOCALE from '@salesforce/i18n/locale'; // e.g., "en-US", "de-DE"
import CURRENCY from '@salesforce/i18n/currency'; // e.g., "USD", "EUR"
Best practices for Deloitte global clients:
- Never hardcode strings in components — always use Custom Labels
- Use
lightning-formatted-numberandlightning-formatted-date-timecomponents which auto-locale-format - Test in multiple languages using Salesforce’s language settings in sandbox
Q20. How do you optimize LWC performance for a component that renders a large list of records?
Answer:
Key techniques:
- Pagination on the server side: Never load all records at once. Implement OFFSET/LIMIT in SOQL or use cursor-based pagination. Return 50-100 records per page.
- Virtual scrolling / infinite scroll: Load the next batch as the user scrolls using
IntersectionObserverAPI.lightning-datatablehas built-inenable-infinite-loading. - Memoize computed properties: Avoid expensive computations in getters that recalculate on every render. Cache results in reactive properties.
- Debounce search/filter inputs: Don’t fire a server call on every keypress. Implement a 300ms debounce.
- Use
lightning-datatablefor tabular data: It’s optimized for rendering large datasets with sorting, pagination, and row actions built in. - Lazy load child components: Use
if:true/lwc:ifdirectives to render heavy components only when needed. - Avoid unnecessary reactive property updates: Batch updates to avoid multiple re-renders within a single user action.
SECTION 3: Integration & APIs
Q21. What is the difference between REST and SOAP APIs in Salesforce integrations? When would you use each?
Answer:
REST API:
- Uses HTTP methods (GET, POST, PATCH, DELETE)
- Returns JSON or XML
- Stateless, lightweight, easy to consume from modern clients
- Supports standard CRUD + bulk operations
- Best for: Modern integrations, mobile apps, web apps, microservices
SOAP API:
- Uses XML-based WSDL contracts
- Strongly typed — great for enterprises needing strict contracts
- Supports all standard operations + some not in REST (e.g.,
merge,undelete,getUserInfo) - Best for: Legacy enterprise systems (ERP, mainframes), Java/.NET integrations that already use SOAP
Deloitte context: In most modern Deloitte Salesforce implementations, REST is preferred. SOAP is used when integrating with legacy SAP, Oracle ERP, or IBM WebSphere systems that predate REST, or when the client’s middleware layer mandates SOAP.
Q22. What is the Salesforce Bulk API? When would you use Bulk API 2.0 vs. REST API?
Answer:
The Bulk API is designed for loading or querying large datasets asynchronously — it processes records in batches in the background without consuming synchronous API limits.
Bulk API 2.0 (recommended):
- Simplified — just upload a CSV, get results
- No batch management needed (Salesforce handles it)
- Supports: insert, update, upsert, delete, hardDelete, query
- Best for: 10,000+ records in a single operation
When to use Bulk API 2.0 vs REST:
| Scenario | Use |
|---|---|
| Loading 500k records from legacy system | Bulk API 2.0 |
| Real-time single record update from UI | REST API |
| Nightly ETL sync of 50k orders | Bulk API 2.0 |
| Mobile app creating a lead | REST API |
| Data migration project | Bulk API 2.0 |
Deloitte tip: Always use Bulk API for data migration projects. REST API for real-time integration flows.
Q23. What is a Named Credential and why should it be used over hardcoded endpoint URLs?
Answer:
A Named Credential is a Salesforce configuration object that stores an external endpoint URL and authentication details (OAuth, Basic Auth, JWT, etc.) securely — separate from code.
Why use Named Credentials:
- Security: Authentication secrets are never stored in Apex code or Custom Settings — they’re encrypted and managed by Salesforce.
- Portability: When deploying from sandbox to production, you don’t need to update hardcoded URLs — the Named Credential is environment-specific.
- No Remote Site Settings needed: Named Credentials automatically bypass Remote Site Settings for their defined endpoint.
- Merged credentials: Callouts using Named Credentials automatically include auth headers — no manual
Authorizationheader building.
// Without Named Credential (BAD)
HttpRequest req = new HttpRequest();
req.setEndpoint('https://api.externalservice.com/v1/data');
req.setHeader('Authorization', 'Bearer ' + someHardcodedToken); // ❌
// With Named Credential (GOOD)
req.setEndpoint('callout:ExternalServiceNC/v1/data'); // ✅
Q24. How do you handle Salesforce outbound callouts and what are the key considerations?
Answer:
Making a callout from Apex:
public class ExternalServiceClient {
public static String fetchData(String endpoint) {
Http http = new Http();
HttpRequest request = new HttpRequest();
request.setEndpoint('callout:MyNamedCredential' + endpoint);
request.setMethod('GET');
request.setTimeout(10000); // 10 second timeout
HttpResponse response = http.send(request);
if (response.getStatusCode() == 200) {
return response.getBody();
} else {
throw new CalloutException('Error: ' + response.getStatus());
}
}
}
Key considerations:
- Cannot callout after DML in same transaction — Use
@future(callout=true)or Queueable withDatabase.AllowsCallouts - Timeout max: 120 seconds
- Max callouts per transaction: 100
- Mock callouts in tests: Implement
HttpCalloutMockinterface — you can’t make real callouts in test context - Error handling: Always handle non-2xx status codes, network timeouts, and parse errors explicitly
- Idempotency: For POST/PATCH, implement retry logic with idempotency keys if the external system supports it
Q25. What is MuleSoft and how does it fit in a Deloitte Salesforce integration architecture?
Answer:
MuleSoft (owned by Salesforce) is an Integration Platform as a Service (iPaaS) — an API-led connectivity platform that acts as an integration middleware layer between Salesforce and other enterprise systems.
Typical Deloitte integration architecture:
SAP ERP ──┐
Oracle DB ─┤──► MuleSoft Anypoint Platform ──► Salesforce
Legacy CRM ┘ (Transformation, Routing,
Error Handling, Retry)
Why MuleSoft over direct Salesforce-to-system integration:
- Decoupling: Systems connect to MuleSoft APIs, not directly to each other — changes in one system don’t break others
- Transformation: MuleSoft handles data format transformation (XML to JSON, field mapping) outside Salesforce
- Reusability: The same MuleSoft API can serve multiple consumers (Salesforce, mobile, portals)
- Monitoring: Centralized integration monitoring, alerting, and retry logic
- Security: Single authentication/authorization gateway
Deloitte preference: On enterprise clients, MuleSoft is the standard integration backbone. Point-to-point integrations (Salesforce directly calling SAP) are avoided for their brittleness.
Q26. What is Salesforce Connect and External Objects? When would you use them?
Answer:
Salesforce Connect allows Salesforce to display data from external systems in real time as if it were native Salesforce data — without copying the data into Salesforce.
External Objects are Salesforce objects backed by external data sources (OData 2.0/4.0, custom adapters). They behave like custom objects in the UI — you can build page layouts, relate them to standard objects, and create reports — but the data lives in an external system.
When to use Salesforce Connect:
- External data is large (millions of records) and copying it would hit storage limits
- Data must always be current — polling/sync introduces staleness
- Data is read-only in the Salesforce context (Salesforce Connect supports limited write-back)
- You need to join external data with Salesforce data in relationships (Indirect Lookup, External Lookup)
Deloitte use cases:
- Showing order history from SAP without migrating all historical orders
- Displaying real-time inventory levels from a warehouse management system
- Surfacing customer support tickets from an on-premise ticketing system
Q27. How would you design an error handling and retry strategy for a Salesforce-to-external integration?
Answer:
Layered error handling strategy:
1. HTTP error classification:
- 4xx (client errors): Don’t retry — the request itself is bad. Log and alert.
- 429 (rate limited): Retry with exponential backoff.
- 5xx (server errors): Retry up to 3 times with backoff; escalate if all fail.
- Timeout: Retry once; if again timeout, put in DLQ.
2. Implementation pattern (Queueable with retry):
public class IntegrationRetryQueueable implements Queueable, Database.AllowsCallouts {
private Integer retryCount;
private String payload;
public void execute(QueueableContext ctx) {
try {
// make callout
} catch (CalloutException e) {
if (retryCount < 3) {
System.enqueueJob(new IntegrationRetryQueueable(payload, retryCount + 1));
} else {
// Log to Integration_Error__c, send alert
}
}
}
}
3. Dead Letter Queue (DLQ):
- After max retries, persist failed payloads to
Integration_Error__ccustom object - Include: payload, error message, timestamp, retry count, record ID
- Build an admin UI for manual retry or triage
4. Idempotency:
- Tag outbound requests with a unique
Correlation-Idheader - Ensures retried calls don’t create duplicate records in the external system
Q28. What is the difference between Inbound and Outbound Salesforce integrations? Give examples of each pattern.
Answer:
Inbound (External → Salesforce): External systems push data INTO Salesforce.
- Patterns: REST API POST, SOAP API, Bulk API uploads, Platform Event publish from external
- Examples: E-commerce website creating Salesforce Leads; ERP syncing invoices as custom records; marketing platform pushing campaign responses
Outbound (Salesforce → External): Salesforce pushes data OUT to external systems.
- Patterns: Outbound Messages (SOAP-based, config-driven), Apex callouts, Platform Event subscribe from external
- Examples: Creating a ticket in ServiceNow when a Case is escalated; updating inventory in SAP when an Order is fulfilled; sending a customer record to a data warehouse after update
Event-driven hybrid:
- Salesforce Change Data Capture → External system subscribes via Streaming API
- External system publishes Platform Event → Salesforce trigger/flow processes it
Deloitte design principle: Always prefer event-driven patterns for decoupled, resilient integrations over point-to-point synchronous callouts when latency allows.
SECTION 4: Data Modeling & SOQL/SOSL
Q29. What is the difference between a Lookup relationship and a Master-Detail relationship in Salesforce?
Answer:
| Feature | Lookup | Master-Detail |
|---|---|---|
| Required field | No | Yes (child always needs parent) |
| Cascade delete | No | Yes (parent deleted = children deleted) |
| Sharing inheritance | No | Yes (child inherits parent’s sharing) |
| Roll-up summary fields | No | Yes (COUNT, SUM, MIN, MAX on master) |
| OWD impact | No | Child’s OWD controlled by master |
| Can reparent | Yes | Controlled by field setting |
| Relationships per object | 40 | 2 |
When to use each:
- Master-Detail: When child records have no meaning without the parent (e.g., Order Line Items → Order) and you need roll-up summaries.
- Lookup: When the relationship is optional or the child can exist independently (e.g., Contact → Account — contacts can exist without accounts).
Deloitte tip: Avoid making relationships Master-Detail unless you actually need roll-up summaries or cascade delete. The mandatory parent constraint can cause issues during data loads and integrations.
Q30. How do you write an efficient SOQL query for large datasets? What is selective querying?
Answer:
Selective queries use indexed fields in the WHERE clause so Salesforce can use database indexes rather than doing a full table scan. A query is selective if it returns fewer than 10% of total records (or fewer than 333k records, whichever is lower) using indexed fields.
Standard indexed fields: Id, Name, OwnerId, RecordTypeId, CreatedDate, SystemModStamp, Custom fields marked as External ID or Unique.
Best practices:
// ❌ Non-selective - full table scan on 5M records
SELECT Id, Name FROM Account WHERE Description LIKE '%Deloitte%'
// ✅ Selective - uses indexed field
SELECT Id, Name FROM Account WHERE CreatedDate >= :startDate AND OwnerId = :currentUser
// ✅ Parent-to-child (sub-query) - only 1 SOQL query
SELECT Id, Name, (SELECT Id, Subject FROM Cases ORDER BY CreatedDate DESC LIMIT 5)
FROM Account WHERE Id IN :accountIds
// Use LIMIT and ORDER BY for large result sets
SELECT Id, Name FROM Opportunity
WHERE StageName = 'Closed Won'
ORDER BY CloseDate DESC
LIMIT 200 OFFSET 0
SOQL best practices at scale:
- Never query without a WHERE clause on large objects
- Use
FOR UPDATEon records you’ll DML within the same transaction (avoids race conditions) - Use
FOR VIEW/FOR REFERENCEto update LastViewedDate without a full DML
Q31. What is a polymorphic relationship in Salesforce? How do you query it?
Answer:
A polymorphic relationship is when a lookup field can reference multiple different object types. The classic example is the WhoId and WhatId fields on Activities (Tasks/Events).
WhoIdcan point to Contact OR LeadWhatIdcan point to Account, Opportunity, Case, or any activity-enabled object
Querying polymorphic fields requires TYPEOF in SOQL:
SELECT Id, Subject,
TYPEOF Who
WHEN Contact THEN FirstName, LastName, Email
WHEN Lead THEN FirstName, LastName, Company
END
FROM Task
WHERE ActivityDate = TODAY
Without TYPEOF, you’d query the common fields (Name, Id) and then check the Type field:
SELECT Id, Who.Type, Who.Name FROM Task
Deloitte context: Custom polymorphic lookups (introduced with External Lookup capabilities) are rare, but understanding Activity polymorphism is critical when building custom activity timelines or integration mappings.
Q32. Explain the WITH SECURITY_ENFORCED clause and stripInaccessible(). When would you use each?
Answer:
Both enforce field-level security (FLS) and object-level security (CRUD) in SOQL/DML, but in different ways.
WITH SECURITY_ENFORCED (SOQL clause):
- Added directly in SOQL query
- Throws a
QueryExceptionif the running user doesn’t have read access to ANY field in the SELECT clause - Fail-fast: query aborts rather than returning partial data
List<Account> accs = [SELECT Id, Name, AnnualRevenue__c FROM Account WITH SECURITY_ENFORCED];
stripInaccessible() (Apex method):
- Strips inaccessible fields from query results or before DML
- Does NOT throw an exception — silently removes fields the user can’t see
- More graceful for building flexible UIs where partial data is acceptable
SObjectAccessDecision decision = Security.stripInaccessible(
AccessType.READABLE, accountList);
List<Account> accessible = decision.getRecords();
When to use which:
- Use
WITH SECURITY_ENFORCEDin internal tools/reports where you want to enforce strict access - Use
stripInaccessible()in community/portal or consumer-facing code where you want graceful degradation
Q33. What is the HAVING clause in SOQL? Give a practical example.
Answer:
HAVING filters aggregate results in SOQL — it’s the aggregate equivalent of WHERE. You use it when you want to filter groups based on aggregate function values (COUNT, SUM, MIN, MAX, AVG).
// Find Accounts with more than 5 open Opportunities
SELECT AccountId, COUNT(Id) oppCount
FROM Opportunity
WHERE StageName != 'Closed Won' AND StageName != 'Closed Lost'
GROUP BY AccountId
HAVING COUNT(Id) > 5
ORDER BY COUNT(Id) DESC
// Find sales reps with total closed revenue > $1M this year
SELECT OwnerId, SUM(Amount) totalRevenue
FROM Opportunity
WHERE CloseDate = THIS_YEAR AND IsWon = true
GROUP BY OwnerId
HAVING SUM(Amount) > 1000000
Deloitte interview tip: Knowing HAVING vs WHERE is a frequent mid-level distinction. WHERE filters individual rows before grouping; HAVING filters groups after aggregation.
Q34. What are External IDs and how are they used in upsert operations?
Answer:
An External ID is a custom field on a Salesforce object marked as “External ID” — it acts as an alternate unique key that references a record’s ID in an external system.
Use in upsert: Database.upsert() uses the External ID field to determine whether to insert (record doesn’t exist) or update (record with that External ID already exists):
Account acc = new Account();
acc.ERP_ID__c = 'SAP-12345'; // External ID field
acc.Name = 'Deloitte Client Corp';
acc.AnnualRevenue = 5000000;
Database.upsert(acc, Account.ERP_ID__c); // Upsert by External ID
Benefits:
- Idempotent data loads — re-running the same load won’t create duplicates
- No need to maintain a mapping table between Salesforce IDs and external IDs
- Critical for data migrations and ongoing sync integrations
In SOQL/relationships: External IDs also enable Relationship Mapping in Bulk API — you can relate records using external IDs instead of Salesforce IDs, which simplifies data loading.
SECTION 5: Security, Sharing & Governance
Q35. Explain the Salesforce security model: OWD, Role Hierarchy, Sharing Rules, Manual Sharing, and Apex Managed Sharing.
Answer:
Salesforce access control works in layers — each layer can only open access, never restrict beyond OWD:
- Object-Level Security (CRUD): Can the user access this object type at all? Controlled by Profiles/Permission Sets.
- Field-Level Security (FLS): Can the user see/edit this specific field? Controlled by Profiles/Permission Sets.
- Record-Level Security (Sharing):
- OWD (Org-Wide Defaults): The most restrictive baseline. Private, Public Read Only, or Public Read/Write.
- Role Hierarchy: Users higher in the hierarchy can see records owned by those below them (if OWD allows upward access).
- Sharing Rules: Automatically grant additional access to groups of users based on record ownership or criteria.
- Manual Sharing: Record owners or admins manually share individual records with specific users/groups.
- Apex Managed Sharing: Programmatically create sharing rules via
Shareobjects (e.g.,AccountShare) for complex dynamic sharing logic.
Apex Managed Sharing example:
AccountShare share = new AccountShare();
share.AccountId = accountId;
share.UserOrGroupId = userId;
share.AccountAccessLevel = 'Edit';
share.RowCause = Schema.AccountShare.RowCause.Manual;
insert share;
Q36. What is the difference between a Profile and a Permission Set? When would you use Permission Set Groups?
Answer:
Profile: A collection of settings and permissions that acts as a baseline for a user. Every user must have exactly one profile. Profiles control: object access, field access, tab visibility, page layout assignment, login hours/IP ranges, and app access.
Permission Set: A supplemental collection of permissions that can be added ON TOP of a user’s profile. Users can have multiple permission sets. Used to grant additional access without changing the profile.
Permission Set Group (PSG): A bundle of Permission Sets that can be assigned together. Simplifies assignment — instead of assigning 5 permission sets to every Sales Manager, create a PSG called “Sales Manager Access” and assign one PSG.
Best practice (Deloitte standard):
- Use the Minimum Access – Salesforce profile as the baseline for all users
- Grant ALL meaningful permissions via Permission Sets / Permission Set Groups
- This makes permissions auditable, reusable, and portable across orgs
- Avoids the proliferation of custom profiles that are hard to maintain
Q37. What is a Permission Set License (PSL) and how does it differ from a User License?
Answer:
User License (e.g., Salesforce, Sales Cloud, Service Cloud): Determines what features and functionality a user can access at the platform level. Assigned one per user.
Permission Set License (PSL): A supplemental license that unlocks specific features that aren’t included in the user’s base license. Multiple PSLs can be assigned to a user.
Examples:
- A user with a standard Salesforce license gets a
Einstein AnalyticsPSL to access Tableau CRM - A user gets an
Identity ConnectPSL to enable SAML federation features - A
CRM Analytics PlusPSL enables advanced analytics features
Why it matters at Deloitte: License management is a significant part of Salesforce governance on enterprise engagements. Assigning features without the correct PSL causes activation failures. License audits are performed during health checks.
Q38. What is Shield Platform Encryption and when would a Deloitte client need it?
Answer:
Shield Platform Encryption encrypts data at rest in Salesforce using customer-managed encryption keys (BYOK). It goes beyond Salesforce’s default encryption to meet specific compliance requirements.
Standard Salesforce encryption: Encrypts data at the infrastructure level (Salesforce manages keys).
Shield Platform Encryption adds:
- Encryption of specific standard and custom fields in the database
- Customer holds and rotates their own encryption keys
- Meets requirements for: PCI DSS, HIPAA, GDPR, FedRAMP
- Encrypts: field data, files, attachments, Chatter data, search indexes
When a Deloitte client needs it:
- Financial services clients storing PAN/CVV or SSN data (PCI DSS)
- Healthcare clients with PHI (HIPAA)
- Government/defense clients (FedRAMP)
- Any client with data sovereignty requirements where they need to revoke Salesforce’s ability to read data by destroying keys
Trade-offs: Shield Platform Encryption impacts functionality — encrypted fields can’t be used in certain filters, formula fields, or workflow criteria. Deloitte architects must assess the impact before enabling.
Q39. How do you prevent SOQL injection in Apex?
Answer:
SOQL injection occurs when user-supplied input is concatenated directly into a SOQL query string, allowing malicious users to manipulate the query.
Vulnerable code:
// ❌ SOQL INJECTION RISK
String name = ApexPages.currentPage().getParameters().get('name');
String query = 'SELECT Id FROM Account WHERE Name = \'' + name + '\'';
List<Account> accounts = Database.query(query);
// If name = "' OR '1'='1", this returns ALL accounts!
Safe approaches:
- Static SOQL with bind variables (preferred):
// ✅ Bind variable - input is never interpreted as SOQL
String name = ApexPages.currentPage().getParameters().get('name');
List<Account> accounts = [SELECT Id FROM Account WHERE Name = :name];
String.escapeSingleQuotes()for dynamic SOQL:
// ✅ Escape the input when dynamic SOQL is unavoidable
String safeName = String.escapeSingleQuotes(name);
String query = 'SELECT Id FROM Account WHERE Name = \'' + safeName + '\'';
- Input validation: Whitelist allowed characters, reject inputs with SQL metacharacters for high-security contexts.
Deloitte note: SOQL injection is on the Salesforce Security Review checklist. Always use bind variables for any user-provided input.
SECTION 6: Automation & Flow
Q40. What is the recommended Salesforce automation strategy in 2026? How does it differ from 5 years ago?
Answer:
The 2026 recommended hierarchy (Salesforce official guidance):
- Flow (Screen Flows, Record-Triggered Flows, Scheduled Flows) — The primary automation tool. Handles most business logic without code.
- Apex Triggers — For complex business logic that Flow can’t handle (advanced queries, callouts, complex object manipulation).
- Invocable Apex — Called from Flow when you need to mix declarative and programmatic logic.
What’s deprecated/sunset:
- Workflow Rules: Retired in 2023. Migrate to Flow.
- Process Builder: Deprecated, no longer accepting new orgs. Migrate to Flow.
- Approval Processes: Still supported, no change.
5 years ago: Process Builder was the primary automation tool alongside Workflow Rules. Apex was reached for even moderately complex logic. Today, Flow’s capabilities (looping, subflows, invocable actions, platform events) handle the vast majority of use cases.
Deloitte interview tip: Be ready to explain how you’d migrate a Process Builder process to Flow and the equivalents (PB “Immediate Action” → Flow “Run Immediately,” PB criteria → Flow entry conditions).
Q41. What are the different types of Flows? Explain when you’d use each.
Answer:
| Flow Type | Trigger | User Interaction | Use Case |
|---|---|---|---|
| Screen Flow | User clicks | Yes | Guided wizards, data entry, multi-step processes |
| Record-Triggered Flow | Record create/update/delete | No | Replacing Workflow Rules, updating fields, sending emails on record change |
| Scheduled Flow | Date/time schedule | No | Batch processing, sending reminders, nightly cleanup |
| Platform Event-Triggered Flow | Platform Event received | No | Integration processing, event-driven automation |
| Autolaunched Flow | Called from Apex/Processes | No | Reusable logic invoked programmatically |
Deloitte common patterns:
- Screen Flow in Community/Experience Cloud: Self-service portals where users complete multi-step forms
- Record-Triggered After-Save Flow: Replacing Process Builder automations (create related records, send emails)
- Scheduled Flow: Sending 7-day renewal reminders by querying records due for renewal
Q42. What is the difference between a “before-save” and “after-save” Record-Triggered Flow? When would you use each?
Answer:
Before-Save (Fast Field Update):
- Runs BEFORE the record is written to the database
- Can update fields on the triggering record itself without an additional DML
- Much faster — no extra save transaction
- Cannot access related records that haven’t been saved yet
- Cannot: create/update/delete other records, make callouts
After-Save:
- Runs AFTER the record is committed to the database
- Can create/update/delete related records
- Can send emails, make callouts (via Apex actions)
- Must update the triggering record via a separate DML (additional save)
Decision guide:
- Updating a field on the same record? → Before-Save (e.g., auto-populating a Full Name field from First + Last)
- Creating a child record? → After-Save (e.g., create a Task when an Opportunity reaches Proposal stage)
- Both? → Use Before-Save for the same-record field updates + After-Save for related record creation
Q43. How do you call Apex from a Flow? What are @InvocableMethod and @InvocableVariable?
Answer:
@InvocableMethod exposes an Apex method to Flow (and Process Builder) as an Action. It must be public static and accept a List.
@InvocableVariable marks properties within an invocable input/output class as variables that Flow can pass in or receive.
public class CreditCheckAction {
@InvocableMethod(label='Run Credit Check' description='Calls external credit bureau API')
public static List<Output> runCreditCheck(List<Input> inputs) {
List<Output> results = new List<Output>();
for (Input inp : inputs) {
Output out = new Output();
out.creditScore = ExternalCreditService.check(inp.ssn);
out.approved = out.creditScore > 650;
results.add(out);
}
return results;
}
public class Input {
@InvocableVariable(required=true)
public String ssn;
}
public class Output {
@InvocableVariable
public Integer creditScore;
@InvocableVariable
public Boolean approved;
}
}
Deloitte best practice: @InvocableMethod is the bridge between Flow (declarative) and Apex (programmatic). Use it to keep business logic in Apex for complex processing while allowing admins to wire it into Flows without developer intervention.
SECTION 7: DevOps, Testing & Deployment
Q44. What is Salesforce DX (SFDX) and how does it change the development workflow?
Answer:
Salesforce DX (SFDX) is Salesforce’s developer experience toolkit that introduces:
- Scratch Orgs: Disposable, source-driven dev/test environments that can be spun up in minutes from a project definition file and destroyed when done.
- Source-Based Development: Project metadata lives in source control (Git) as the source of truth — not the org.
- Salesforce CLI (sf/sfdx): Command-line tools for org operations, metadata retrieval, deployment, and testing.
- Unlocked Packages: Modular packaging of metadata with version tracking and dependency management.
Traditional org-based workflow vs. SFDX:
| Aspect | Traditional | SFDX |
|---|---|---|
| Source of truth | Sandbox org | Git repository |
| Dev environment | Shared sandbox | Individual scratch orgs |
| Deployment | Change sets | CI/CD pipelines (GitHub Actions, Jenkins) |
| Packaging | Unmanaged packages | Unlocked packages |
Deloitte standard: All major Salesforce engagements use SFDX with Git (typically GitHub or Azure DevOps) and CI/CD pipelines for automated deployment and test execution.
Q45. What is a good Apex test strategy? What does Deloitte expect in terms of test coverage and quality?
Answer:
Salesforce minimum: 75% code coverage to deploy to production. But at Deloitte, the bar is much higher.
Deloitte test quality standards:
- Coverage target: 90%+ coverage, with meaningful assertions — not just “coverage for coverage’s sake.”
- Test classes should:
- Use
@TestSetupfor shared test data - Test both positive (happy path) and negative (error cases, validation failures) scenarios
- Test bulk behavior — always test with 200 records, not just 1
- Use
Test.startTest()/Test.stopTest()to reset governor limits and force async execution - Assert specific outcomes — not just “no exception was thrown”
- Use
- Mock external services:
- Use
HttpCalloutMockfor HTTP callouts - Use
StubProvideror mock frameworks for service layer isolation
- Use
- Avoid:
SeeAllData=true(flaky, environment-dependent)- Testing private methods (test through public interface)
- Relying on real data in the org
@isTest
static void testBulkAccountUpdate() {
List<Account> accounts = new List<Account>();
for (Integer i = 0; i < 200; i++) {
accounts.add(new Account(Name = 'Test Account ' + i, Industry = 'Technology'));
}
insert accounts;
Test.startTest();
AccountService.updateIndustry(accounts, 'Finance');
Test.stopTest();
List<Account> updated = [SELECT Industry FROM Account WHERE Id IN :accounts];
for (Account a : updated) {
System.assertEquals('Finance', a.Industry, 'Industry should be updated to Finance');
}
}
Q46. What is a CI/CD pipeline for Salesforce? Describe a typical Deloitte pipeline.
Answer:
A CI/CD (Continuous Integration/Continuous Deployment) pipeline automates the process of validating, testing, and deploying Salesforce metadata from source control to environments.
Typical Deloitte pipeline (GitHub Actions or Azure DevOps):
Developer pushes feature branch
↓
[CI - Pull Request Stage]
1. Lint Apex with PMD (static code analysis)
2. Validate metadata against a validation org (--checkonly)
3. Run all Apex test classes
4. Code review required
↓
[Merge to develop]
5. Auto-deploy to SIT (System Integration Testing) sandbox
↓
[Merge to release branch]
6. Auto-deploy to UAT sandbox
7. Run regression test suite
↓
[Manual approval]
8. Deploy to Production (with rollback plan)
Key tools:
- Salesforce CLI (sf):
sf project deploy start,sf apex run test - PMD: Apex static analysis (detects SOQL injection, missing WITH SECURITY_ENFORCED, etc.)
- GitHub Actions / Azure Pipelines: Pipeline orchestration
- Copado / Gearset / Flosum: Salesforce-native DevOps platforms commonly used by Deloitte for complex multi-org pipelines
Q47. How do you handle deployment of destructive changes in Salesforce?
Answer:
Destructive changes are metadata components being deleted from an org (removing a custom field, deleting a Flow, removing an Apex class).
Using Salesforce CLI:
# Create destructiveChanges.xml
# Deploy with destructive manifest
sf project deploy start \
--manifest package.xml \
--post-destructive-changes destructiveChanges.xml \
--target-org production
destructiveChangesPre.xml vs destructiveChangesPost.xml:
- Pre: Deletions happen BEFORE the package is deployed (use for removing components the new code no longer depends on)
- Post: Deletions happen AFTER the package is deployed (use for removing components the old code depended on)
Deloitte precautions:
- Never deploy destructive changes without a backup — export the component being deleted first
- Check data dependencies — deleting a custom field permanently deletes its data in all records
- Test in sandbox first — validate the destructive change doesn’t break other automations
- Schedule during low-traffic windows — destructive deployments can briefly lock the org
- Get client sign-off — on consulting engagements, client approval is mandatory before any data-destructive operation
SECTION 8: Scenario / Consulting-Mindset Questions
Q48. A client reports that their Salesforce org has slowed down significantly after a recent deployment. How do you diagnose and resolve this? (Scenario question)
Answer:
Step 1: Gather context
- What was deployed? (Apex triggers, Flows, new automation?)
- Which operations are slow? (Record save? Report? Page load?)
- Is it all users or specific profiles/record types?
Step 2: Use Salesforce debugging tools
- Debug Logs: Enable for the affected user/profile. Look for: high CPU time, excessive SOQL queries, nested loops.
- Event Monitoring: Check
ApexExecutionandApexTriggerevents for transaction times above baseline. - Setup Audit Trail: Confirm what was changed in the deployment.
- Flow Interview Errors / Debug Logs: If Flows are involved, check for infinite loops or deeply nested subflows.
Step 3: Common culprits
- Trigger without bulkification: A new trigger doing SOQL inside a loop that’s fine for 1 record but crawls for 50.
- New Record-Triggered Flow with complex criteria running on every update.
- After-save automation creating cascading updates on related records, triggering more automation.
- Non-selective SOQL added to a trigger that runs a full table scan.
Step 4: Resolve
- Fix the non-bulkified trigger / non-selective query
- Add a Flow entry criteria to filter the Flow to only relevant records
- Consolidate redundant automations
Deloitte approach: Always communicate findings to the client before making changes, provide a root cause analysis document, and propose a fix with estimated effort. Never just “fix it silently.”
Q49. A client wants to give external partners access to specific Salesforce data via an API. How would you design the solution? (Architecture question)
Answer:
Requirements clarification I’d ask:
- What data? (Read-only or read-write?)
- Authentication method? (OAuth 2.0 preferred? API keys?)
- Volume? (Real-time queries or bulk exports?)
- Partner type? (Trusted internal partner vs. third-party vendor?)
Recommended solution: Salesforce Connected App + REST API + Named Credentials
Architecture:
- Create a Connected App in Salesforce for each partner (or partner category)
- OAuth 2.0 Client Credentials Flow for server-to-server (no user login needed): Partner gets
client_id+client_secret→ exchanges for access token → calls Salesforce REST API - Create a dedicated Integration User with a Permission Set that grants ONLY the required object/field access (principle of least privilege)
- Expose data via Custom REST Apex endpoint if you need to:
- Aggregate data from multiple objects
- Apply business logic before returning data
- Control response format
@RestResource(urlMapping='/partner/accounts/*')
global with sharing class PartnerAccountAPI {
@HttpGet
global static List<Account> getAccounts() {
// Only return fields the partner should see
return [SELECT Id, Name, Industry, BillingCity
FROM Account
WHERE Partner_Accessible__c = true
WITH SECURITY_ENFORCED];
}
}
- Rate limiting: Consider Salesforce API rate limits (standard: 100k calls/24hr for Enterprise). For high-volume partners, use Experience Cloud + Headless API or add MuleSoft throttling.
- Audit: Enable Event Monitoring to track all API calls by partner.
Q50. You’ve joined a Deloitte project midway. The existing Salesforce org has no documentation, mixed automation (Workflows, Process Builder, Flows, and Triggers all on the same object), and poor test coverage. How would you approach stabilizing it? (Consulting-mindset question)
Answer:
This is a “technical debt remediation” scenario — common at Deloitte on legacy client orgs.
Phase 1: Assessment (Week 1-2)
- Inventory all automation: Use tools like Salesforce Optimizer, Elements.cloud, or FieldTrip to document all Triggers, Flows, Process Builders, Workflow Rules, and Validation Rules per object.
- Map the execution order: Document which automation fires in what order on key objects (Account, Opportunity, Case).
- Identify conflicts: Look for automation that updates the same field, causing loops or unexpected overwrites.
- Assess test coverage: Run
sf apex get coverageor check the Apex Test Execution page. Flag all classes below 80%. - Interview business stakeholders: Understand WHAT each automation is supposed to do (often the only documentation).
Phase 2: Stabilize (Weeks 3-6)
- Consolidate triggers: If multiple triggers exist on one object, merge into one using the Trigger Handler pattern.
- Disable deprecated automation: Turn off Workflow Rules / Process Builder processes, replace with equivalent Flows (document the migration).
- Fix test coverage: Start with the lowest-coverage classes that are most at risk. Write meaningful tests, not just coverage padding.
- Add a Trigger Bypass mechanism: Custom Metadata-based bypass so automation can be disabled during data loads without deployment.
Phase 3: Document & Govern
- Create an Automation Inventory living document (Confluence or SharePoint)
- Establish a change governance process — no new automation without peer review
- Set up a CI/CD pipeline so future changes go through code review and automated testing
- Present findings and roadmap to client in a Technical Debt Report with prioritized remediation
Key Deloitte principle: Never just “fix” things silently. Always present findings, get approval, and document. Clients pay for transparency and a clear plan, not just execution.
🎯 Quick Tips for Your Deloitte Interview
Behavioral expectations:
- Deloitte interviewers value the STAR method (Situation, Task, Action, Result) for scenario questions
- Connect technical answers to client impact — cost savings, risk reduction, velocity improvement
- Demonstrate awareness of governance, scalability, and maintainability — not just “does it work”
Technical red flags to avoid:
- Saying “I always use triggers” for everything — show you consider Flow-first
- Ignoring governor limits in theoretical solutions
- Not mentioning security (FLS, CRUD, sharing) in data access scenarios
Top topics to review additionally:
- Salesforce CPQ (if applying to product/revenue cloud teams)
- Experience Cloud (Community portals)
- Tableau CRM / Analytics Studio
- Health Cloud / Financial Services Cloud (practice-specific)
Last updated: 2026 | Targeted for: 3–5 years Salesforce Developer experience
Best of Luck
Trusted by 2000+ learners to crack interviews at TCS, Infosys, Wipro, EY, and more.
Want more Real Salesforce Interview Q&As?
- For Beginners (1–4 Yrs Experience) → https://trailheadtitanshub.com/100-real-salesforce-scenario-based-interview-questions-2025-edition-for-1-4-years-experience/
- For Intermediate Developers (4–8 Yrs Experience) → https://trailheadtitanshub.com/100-real-time-salesforce-scenario-based-interview-questions-2025-edition-for-4-8-years-experience/
For All Job Seekers – 500+ Questions from Top Tech Companies → https://trailheadtitanshub.com/500-real-interview-questions-answers-from-top-tech-companies-ey-infosys-tcs-dell-salesforce-more/
- Student Journey – 34 Days to Crack Salesforce Interview → https://trailheadtitanshub.com/crack-the-interview-real-questions-real-struggles-my-students-34-day-journey/
Mega Interview Packs:
- 600 Real Q&A (Recruiter Calls) → https://trailheadtitanshub.com/salesforce-interview-mega-pack-600-real-questions-from-recruiter-calls-with-my-best-performing-answers/
- 100 Real-Time Scenarios (Admin + Apex + LWC + Integration) → 100 Real-Time Salesforce Interview Questions & Scenarios (2026 Edition) – Admin, Apex, SOQL, LWC, VF, Integration – Trailhead Titans Hub
Career Boosters:
- Salesforce Project (Sales Cloud) → https://trailheadtitanshub.com/salesforce-project-sales-cloud/
- Resume Templates (ATS-Friendly) → https://trailheadtitanshub.com/salesforce-resume-templates-that-work-beat-ats-impress-recruiters/
Visit us On→ www.trailheadtitanshub.com